K8s 服务资源
服务概念
在 K8s 中,不再使用记录 pod IP 的方式来实现 pod 之间的通信,因为 pod 是活动的,会随着调度分配而更换 IP 地址。K8s 提供了一种名为服务(Service)的资源,用于解决 pod 之间的通信问题。每个服务实际上就是微服务架构中的一个微服务。
服务的主要工作是通过标签选择器选取一组 pod 对象,并为这组 pod 提供一个固定的入口点(固定 IP),客户端通过访问该地址来访问这组 pod 中的任意一个对象。
如果集群中存在 DNS 服务,它会在创建服务时为其自动配置一个 DNS 名称,该名称对应服务的 ClusterIP 地址,以便客户端进行服务发现。实质上,服务充当了一个四层代理服务器。
服务原理
每个 Service 都有自己稳定的 IP 地址和端口,客户端通过连接该 IP 和端口来使用服务。IP 地址是虚拟的,没有分配给任何网络接口,并且当数据包离开节点时,也不会被标记为数据包的源或目的地 IP 地址,因此无法使用 ping 命令连接到 Service 的 IP。
与 Service 相关的所有事情都由运行在每个节点上的 kube-proxy 处理。在最初的实现中,代理模式采用用户空间代理,对于每个传入的连接,连接到一个 pod。
现在采用的是 iptables 代理模式,具有更好的性能。当在 API 服务器中创建一个 Service 时,会立即分配虚拟 IP 地址。然后,API 服务器会通知所有节点上的 proxy 客户端有关新服务的信息。每个 proxy 都会在自己所在的节点上建立可寻址的服务。这是通过建立 iptables 规则来实现的,确保目标为服务的 IP/端口对的数据包被解析,目的地址被修改,从而将数据包重定向到支持该服务的一个 pod 上。
除了监视 Service 的更改,proxy 还监视 Endpoint 对象的更改。Endpoint 对象会在每次新创建或删除 pod 时发生变化,以及 pod 的就绪状态或标签发生变化时,将其纳入或移出服务范畴。
如下图所示,proxy 在 Service 中的作用:
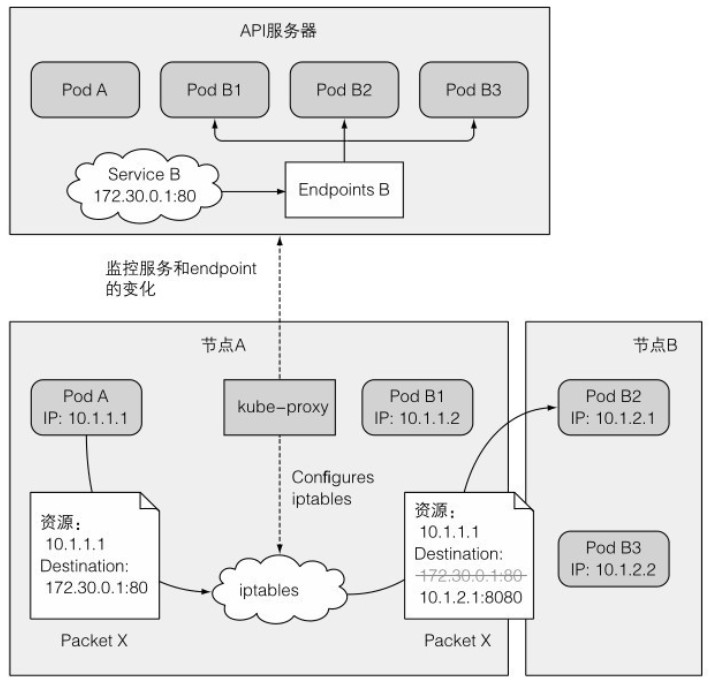
上述示例中,一个数据包从节点 A 的 pod A 发送到服务 B。节点 A 的 iptables 规则将数据包的目标地址设置为服务的 IP 和端口(172.30.0.1:80),根据规则匹配,将匹配到的地址和端口(172.30.0.1:80)替换为随机选中的 pod B2 的 IP 和端口,就好像客户端的 pod A 直接将数据包发送给 pod B,而不经过 Service。
运行在每个节点上的 Proxy 进程实际上是一个智能的软件负载均衡器,内部实现了服务的负载均衡和会话保持机制。
外部连接的特性
当客户端通过节点端口连接到服务时,随机选择的 pod 并不一定在接收连接的同一节点上运行。例如,接收服务的 pod 运行在 node1,而服务在 node2,这会导致不必要的跳转。可以通过将服务配置为仅将外部通信重定向到接收连接的节点上运行的 pod。
具体操作是将服务的 spec.externalTrafficPolicy 修改为 Local。如果节点上没有本地 pod 存在,则连接将挂起,因此需要确保负载均衡器将连接转发给至少具有一个 pod 的节点。
然而,这种配置会引发一个问题,即原本均匀分配给 pod 的流量将按节点平均分配。例如,一个节点有一个 pod,另一个节点有两个 pod,原本每个 pod 接收的流量占比为 1/3。设置流量不转发后,一个 pod 承担了 1/2 的流量,而另外两个 pod 分别承担了 1/4 的流量。
在没有配置流量不转发的情况下,当通过节点端口接收连接时,会对数据包执行源网络地址转换(SNAT),因此数据包的源 IP 地址会发生改变,后端的 pod 无法看到实际的客户端 IP 地址。而使用上述配置可以保留客户端 IP,因为接收连接的节点和目标 pod 节点之间没有额外的跳转。
排除连接故障
首先,确保从集群内部连接到服务时使用的是集群 IP,而不是从外部进行连接。
请避免使用 ping 来判断服务是否可访问,因为服务的集群 IP 是虚拟的。
如果已经定义了就绪探针,请确保探针返回成功,否则该 pod 将不会被视为服务的一部分。
要确认某个容器是否属于服务,请使用 get endpoints 命令来检查相应的端点对象。
如果通过完全限定域名(FQDN)无法访问服务,请尝试使用集群 IP 进行访问。
可以尝试直接连接到 pod 的 IP 地址,以确认该 pod 是否正在正确的端口上接收连接。
如果甚至无法通过 pod 的 IP 访问应用程序,请确保应用程序没有仅绑定到本地主机。
基本操作
服务(Services)使用标签(Labels)来选择 Pod。以下简称 SVC。
创建 SVC
假设已经启动了一组 Pod,其标签为 app=kubia,可以通过命令 kubectl expose 来创建服务。不过更推荐使用 YAML 文件:
[root@server4-master ~]$ vi kubia-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: kubia其中 80 端口用于对外访问,8080 映射到容器端口,并通过标签 app=kubia 选择 Pod。
创建并查看服务:
[root@server4-master ~]$ kubectl create -f kubia-svc.yaml
[root@server4-master ~]$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17h
kubia ClusterIP 10.107.244.106 <none> 80/TCP 8s可以看到服务已经分配了一个内部集群 IP 地址 10.107.244.106,访问端口为 80。
测试服务
由于是内部集群地址,只有集群中的 Pod 可以访问。可以使用 kubectl exec 命令在 Pod 中执行 curl 命令:
[root@server4-master ~]$ kubectl exec kubiaex-f4wkw -- curl -s 10.107.244.106
You've hit kubiaex-nj968
[root@server4-master ~]$ kubectl exec kubiaex-f4wkw -- curl -s 10.107.244.106
You've hit kubiaex-ptws9从结果可以看到请求连接到后端的随机一个 Pod。
亲和性
可以配置服务的会话亲和性,这样会使服务代理将同一 IP 的请求转发到同一个 Pod 中:
[root@server4-master ~]$ vi kubia-svc.yaml
spec:
sessionAffinity: ClientIP亲和性配置 sessionAffinity 值默认为 None。由于 Kubernetes 服务不是在 HTTP 层面上工作,它只处理 TCP 和 UDP 包,所以会话亲和性不能基于 cookie。
暴露多端口
可以在服务中暴露多个端口。必须设置端口名称:
[root@server4-master ~]$ vi kubia-svc.yaml
spec:
ports:
- name: http
port: 80
targetPort: 8080
- name: https
port: 443
targetPort: 8443命名引用
如果 Pod 配置中对端口取了名:
[root@server4-master ~]$ vi kubia-rs.yaml
spec:
containers:
ports:
- name: http
containerPort: 8080
- name: https
containerPort: 8443那么在服务配置中可以直接引用:
[root@server4-master ~]$ vi kubia-svc.yaml
spec:
ports:
- name: http
port: 80
targetPort: http
- name: https
port: 443
targetPort: https这样做的好处是,当容器更换端口号时,无须更改服务的配置。
服务发现
服务可以提供稳定的 IP 地址来访问 Pod,只要服务存在, IP 就不会变化。但客户端 Pod 要获得服务的 IP 和端口需要进行配置。
环境变量
如果服务先于 Pod 创建,Pod 创建时 Kubernetes 会初始化一系列环境变量,指向已存在的服务。Pod 上的进程可以根据环境变量获取服务的 IP 地址和端口号。
重新运行 Pod 后再查看环境变量:
[root@server4-master ~]$ kubectl delete -f kubia-rs.yaml
[root@server4-master ~]$ kubectl create -f kubia-rs.yaml
[root@server4-master ~]$ kubectl exec kubiaex-5s68q -- env
KUBIA_PORT=tcp://10.107.244.106:80
KUBIA_SERVICE_HOST=10.107.244.106
KUBIA_SERVICE_PORT=80
KUBIA_PORT_80_TCP_PROTO=tcp
KUBIA_PORT_80_TCP_ADDR=10.107.244.106
KUBIA_PORT_80_TCP=tcp://10.107.244.106:80
KUBIA_PORT_80_TCP_PORT=80上面显示的环境变量是创建服务后才有的,它们指向了服务 kubia 的 IP 地址和端口。此外,还有 Kubernetes 服务的环境变量。
通过 DNS 发现
Kubernetes 使用 CoreDNS 作为默认的 DNS 服务。每个运行的 Pod 都会在 /etc/resolv.conf 中写入 DNS 服务的地址:
[root@server4-master ~]$ kubectl -n kube-system describe service/kube-dns
IP: 10.96.0.10
[root@server4-master ~]$ kubectl exec -it kubiaex-5s68q -- cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5Pod 是否使用内部 DNS 策略由 spec.dnsPolicy 来决定:
[root@server4-master ~]$ kubectl get po kubiaex-5s68q -o yaml
spec:
dnsPolicy: ClusterFirst客户端的 Pod 在知道服务名称的情况下,可以通过全限定域名(Fully Qualified Domain Name,FQDN)来访问,而不用依靠环境变量。例如,服务的全名是 kubia.default.svc.cluster.local,通过 Pod 中的容器访问这个地址:
root@kubiaex-5s68q:/# curl http://kubia.default.svc.cluster.local
You've hit kubiaex-bwzb9FQDN 分为三部分:kubia 为主机名,default 为对应的命名空间,svc.cluster.local 是所有集群本地服务名称中使用的可配置集群域后缀。
如果要与同一命名空间下的资源通信,可以省略后缀,直接通过主机名进行通信:
root@kubiaex-5s68q:/# curl http://kubia
You've hit kubiaex-bwzb9
root@kubiaex-5s68q:/# ping kubia
PING kubia.default.svc.cluster.local (10.107.244.106): 56 data bytes暴露内部服务
服务主要作用是将集群内的服务向外公开,让外部客户端可以访问它们。如下图所示:
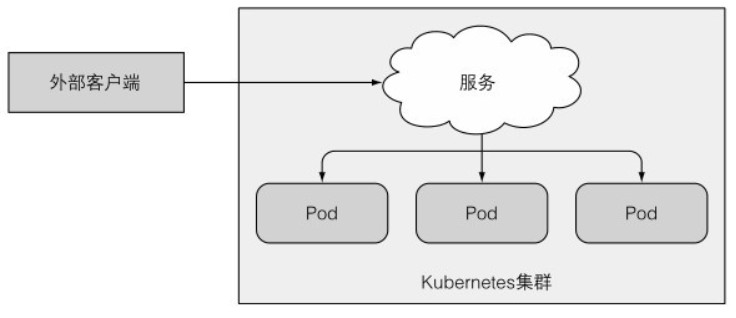
有几种方式可以从外部访问服务:
-
将服务类型设置为 NodePort
每个集群节点都会打开一个端口,并将流量转发重定向到基础服务。该服务只能在内部集群的 IP 和端口上访问,但也可以通过所有节点上的专用端口访问。
-
将服务类型设置为 LoadBalancer
LoadBalancer 是 NodePort 类型的一种扩展,它允许通过一个专用的负载均衡器来访问服务,该负载均衡器由云基础设施提供。负载均衡器将流量重定向到跨所有节点的节点端口,客户端可以通过负载均衡器的 IP 连接到服务。
-
创建一个 Ingress 资源
Ingress 资源可以通过一个 IP 地址公开多个服务,它运行在 HTTP 层(第 7 层),因此可以提供更多的功能。
最常用的端口暴露方式是 NodePort。一般的应用端口可以通过 Nginx 做反向代理,而不需要直接暴露出去。
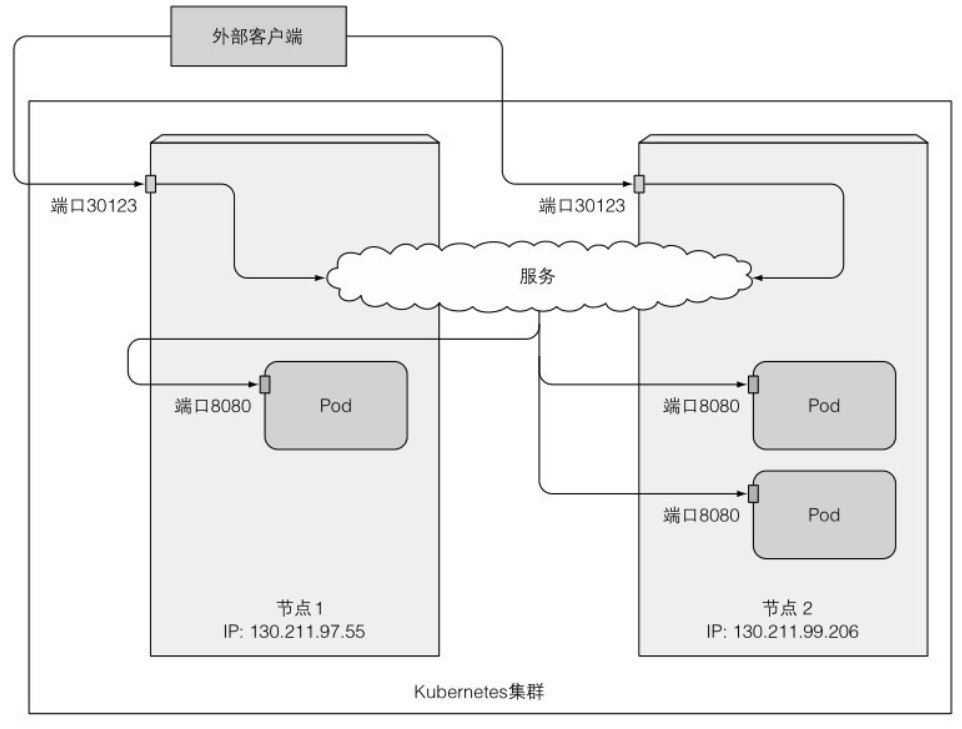
NodePort
NodePort 类型的服务可以通过任何节点的 IP 和端口进行访问,同时也可以通过服务的内部集群 IP 进行访问,两者互不冲突。默认情况下,NodePort 可用的端口范围是从 30000 到 32767。示意图如下所示:
创建服务配置文件时,除了将类型设置为 NodePort,还需要定义三个端口:
[root@server4-master ~]$ vi kubia-np.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
nodePort: 30123
selector:
app: kubia其中,port 端口 80 代表集群内部访问端口,targetPort 端口 8080 代表 Pod 中服务监听的端口,这两个端口的定义与普通服务相同。而额外的 nodePort 端口 30123 是用于外部访问的端口。如果不设置 nodePort,Kubernetes 会使用随机端口。
[root@server4-master ~]$ kubectl create -f kubia-np.yaml
service/kubia-nodeport created启动后,可以通过浏览器访问地址 http://任意节点 IP:30123/ 来打开服务。可以使用 JSONPath 选择器来获取所有节点的 IP:
[root@server4-master ~]$ kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}'
192.168.2.204 192.168.2.205 192.168.2.206需要注意的是,当节点发生故障时,无法访问该节点。因此,在选择端口暴露方式时,应优先考虑使用 LoadBalancer。
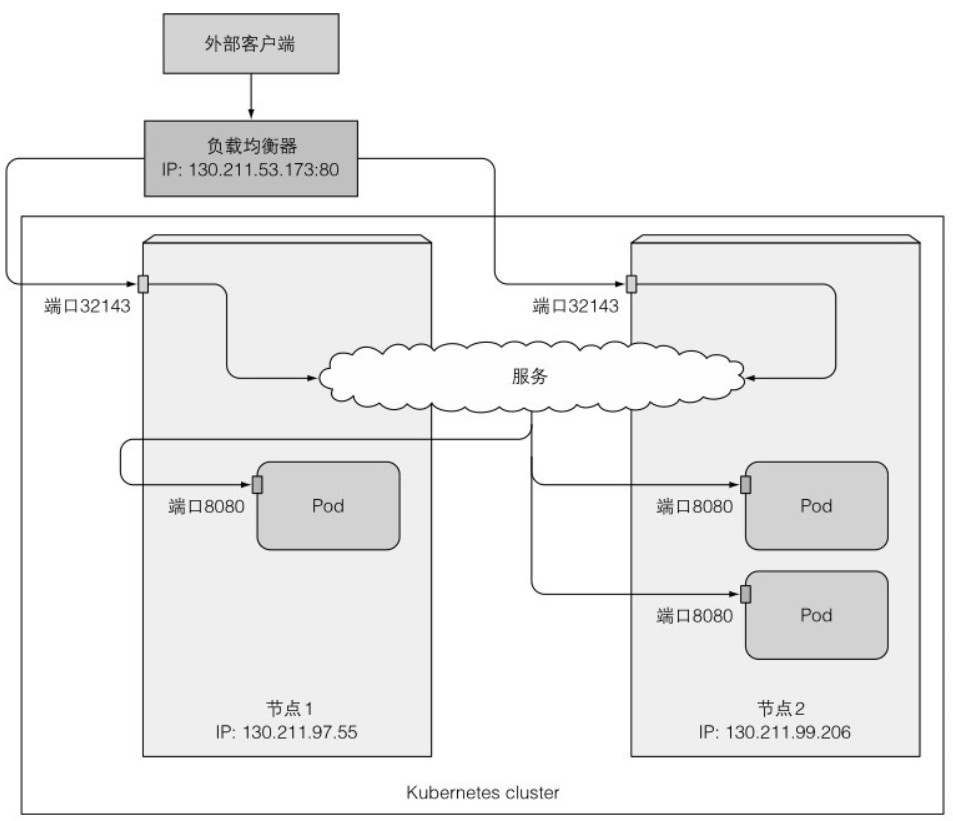
LoadBalance
负载均衡器具有唯一的 IP 地址,并将所有连接重定向到服务。LoadBalancer 服务是 NodePort 服务的扩展,如果 Kubernetes 在不支持负载均衡器服务的环境中运行,服务仍将以 NodePort 模式工作。其工作原理如下图所示:
可以创建一个 LoadBalancer 类型的服务:
[root@localhost ~]$ vi kubia-lb.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia-loadbalancer
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
[root@localhost ~]$ kubectl create -f kubia-lb.yaml
service/kubia-loadbalancer created只需将服务类型设置为 LoadBalancer,服务将从集群基础架构中获取负载均衡器,并将其 IP 地址写入服务的 EXTERNAL-IP 字段。
通过浏览器访问时,您会发现每次都会连接到同一个 Pod,这是因为服务在连接级别上工作。因此,首次建立连接时会选择一个随机集群,之后所有的数据包都会发送到同一个集群,直到连接关闭。
Ingress
使用 Ingress 只需要一个公网 IP 地址就能为所有服务提供访问,Ingress 会根据请求的主机名和路径决定转发到的服务。
Ingress 作用在网络第七层,因此能实现基于 cookie 的会话亲和性等功能,但相对于作用在第四层协议的服务,转发效率较低。
Ingress 的工作原理如下图所示:
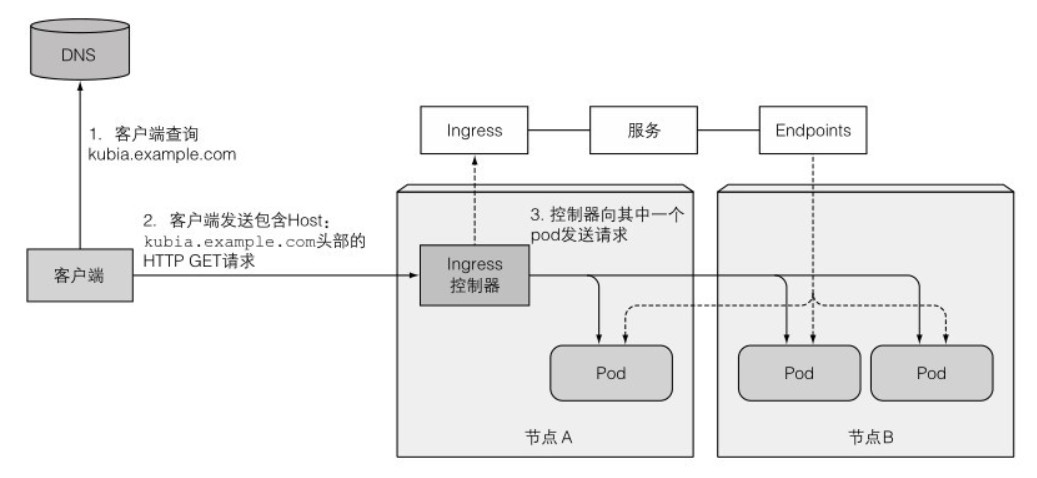
要让 Ingress 资源正常工作,需要配合 Ingress 控制器。可以通过官方提供的 YAML 文件直接部署 Ingress,可以选择基于 Nginx、Envoy、Haproxy、Vulcand 和 Traefik 等作为反向代理:
[root@localhost ~]$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/mandatory.yaml
namespace/ingress-nginx created
configmap/nginx-configuration created
configmap/tcp-services created
configmap/udp-services created
serviceaccount/nginx-ingress-serviceaccount created
clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole created
role.rbac.authorization.k8s.io/nginx-ingress-role created
rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding created
clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding created
deployment.apps/nginx-ingress-controller created查看 YAML 内容后,将自动创建一个属于 ingress-nginx 命名空间的 nginx-ingress-controller 控制器的 Pod,然后创建服务:
[root@localhost ~]$ kubectl get pods --all-namespaces -l app.kubernetes.io/name=ingress-nginx --watch
NAMESPACE NAME READY STATUS RESTARTS AGE
ingress-nginx nginx-ingress-controller-7995bd9c47-8v8rj 0/1 ContainerCreating 0 75s
ingress-nginx nginx-ingress-controller-7995bd9c47-8v8rj 0/1 Running 0 88s接着创建服务:
[root@localhost ~]$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/provider/baremetal/service-nodeport.yaml
service/ingress-nginx created
[root@k8s-master ~]$ kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
nginx-ingress-controller-7995bd9c47-8v8rj 1/1 Running 0 3h6m
[root@k8s-master ~]$ kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 10.98.41.161 <none> 80:30112/TCP,443:30970/TCP 105m建立 YAML 文件来绑定后端服务:
[root@localhost ~]$ vi kubia-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia-ingress
spec:
rules:
- host: kubia.exp.com
http:
paths:
- path: /
backend:
serviceName: kubia
servicePort: 80将虚拟域名 kubia.exp.com 映射到 Ingress 控制器的节点 IP(192.168.2.113-115 kubia.exp.com)。配置将所有请求发送到 kubia 服务的 80 端口。云服务商要求 Ingress 指向一个 NodePort 服务,但实际上可以指向任意服务。
[root@localhost ~]$ kubectl create -f kubia-ingress.yaml
ingress.extensions/kubia-ingress created
[root@localhost ~]$ kubectl get ingresses
NAME HOSTS ADDRESS PORTS AGE
kubia-ingress kubia.exp.com 80 59s
[root@k8s-master ~]$ kubectl describe ingress kubia-ingress
Name: kubia-ingress
Namespace: default
Address:
Default backend: default-http-backend:80 (<none>)
Rules:
Host Path Backends
---- ---- --------
kubia.exp.com
/ kubia:80 (10.244.1.28:8080,10.244.2.43:8080,10.244.2.44:8080)
Annotations:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CREATE 2m22s nginx-ingress-controller Ingress default/kubia-ingress通过浏览器访问 kubia.exp.com:30112 即可访问 kubia 服务。
客户端与控制器之间的通信采用 HTTPS 加密,而控制器与后端 Pod 之间的通信则不需要加密。运行在 Pod 上的应用程序不需要支持 TLS。例如,如果 Pod 上运行着 Web 服务器,它只需要接收 HTTP 通信,并让 Ingress 控制器负责处理与 TLS 相关的所有内容。只需将证书和私钥附加到 Ingress 上,这两个资源存储在 Secret 中,然后在 Ingress 的配置文件中引用它们:
[root@k8s-master ~]$ openssl genrsa -out tls.key 2048
[root@k8s-master ~]$ openssl req -new -x509 -key tls.key -out tls.crt -subj /C=CN/ST=Beijing/L=Beijing/O=DevOps/CN=kubia.exp.com
[root@k8s-master ~]$ kubectl create secret tls kubia-secret --cert=tls.crt --key=tls.key
[root@k8s-master ~]$ kubectl get secret
NAME TYPE DATA AGE
default-token-5wkq2 kubernetes.io/service-account-token 3 25h
kubia-secret kubernetes.io/tls 2 30s
tomcat-ingress-secret kubernetes.io/tls 2 55m重新创建 Ingress,使用 HTTPS 协议将 kubia 绑定到 kubia.exp.com:
[root@k8s-master ~]$ vi kubia-tls.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-kubia
namespace: default
spec:
tls:
- hosts:
- kubia.exp.com
secretName: kubia-secret
rules:
- host: kubia.exp.com
http:
paths:
- path:
backend:
serviceName: kubia
servicePort: 8080
[root@k8s-master ~]$ kubectl create -f kubia-tls.yaml
ingress.extensions/ingress-kubia created
[root@k8s-master ~]$ kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
ingress-kubia kubia.exp.com 80, 443 29s
ingress-myapp myapp.along.com 80 65m
ingress-tomcat tomcat.along.com 80 60m
ingress-tomcat-tls tomcat.along.com 80, 443 58m
kubia-ingress kubia.exp.com 80 10m使用浏览器访问 HTTPS 地址:https://kubia.exp.com:30970/ 进行验证。
可以通过设置多个路径来将访问路径转发到不同的服务:
...
http:
paths:
- path: /
backend:
serviceName: kubia
servicePort: 80
- path: /admin
backend:
serviceName: admin
servicePort: 80同样,可以设置多个规则来将子域名转发到不同的服务:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia-ingress
namespace: default
spec:
rules:
- host: kubia.exp.com
http:
paths:
- path: /
backend:
serviceName: kubia
servicePort: 80
rules:
- host: app.exp.com
http:
paths:
- path: /
backend:
serviceName: app
servicePort: 80
- path: /api
backend:
serviceName: api
servicePort: 80除了使用 NodePort、LoadBalancer 等方式来暴露单个服务,还可以使用 Ingress 来暴露服务:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
backend:
serviceName: my-svc
servicePort: 80这样,通过外网访问 80 端口即可直接转发到 my-svc 服务。
指向外部服务
SVC 也可以将服务的地址重定向到集群外部网络的地址和端口,在集群中的 pod 可以像连接内部服务一样连接到外部服务。如下图所示:
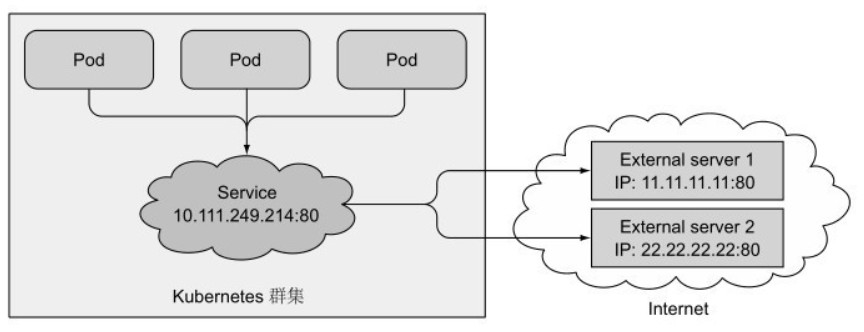
Endpoint
SVC 通过 Endpoint(以下简称 EP)资源与 pod 进行连接,一般指向 pod 的 IP 地址和端口列表:
[root@server4-master ~]$ kubectl describe svc kubia
Endpoints: 10.244.191.210:8080,10.244.191.211:8080,10.244.244.209:8080也可以直接查询 EP 资源:
[root@server4-master ~]$ kubectl get endpoints kubia
NAME ENDPOINTS AGE
kubia 10.244.191.210:8080,10.244.191.211:8080,10.244.244.209:8080 100m
[root@server4-master ~]$ kubectl describe endpoints kubia
Name: kubia
Namespace: default
Labels: <none>
Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2021-11-03T11:45:07Z
Subsets:
Addresses: 10.244.191.210,10.244.191.211,10.244.244.209
NotReadyAddresses: <none>
Ports:
Name Port Protocol
---- ---- --------
<unset> 8080 TCPEP 的作用是存储通过 pod 选择器获取的 pod 地址和端口,并提供给服务调用。
配置 EP
可以分别创建 SVC 和 EP 资源来自定义要转发到的地址列表。先创建一个没有选择器的服务,并指定 EP 的目标端口为 80:
[root@server4-master ~]$ vi outside-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: outside
spec:
ports:
- name: http
port: 80创建一个 EP 来指定地址列表。名称需要与 SVC 的一致:
[root@server4-master ~]$ vi outside-ep.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: outside
subsets:
- addresses:
- ip: 11.11.11.11
- ip: 22.22.22.22
ports:
- port: 80分别部署后,SVC 就具有了转发到外部服务的功能:
[root@server4-master ~]$ kubectl create -f outside-svc.yaml -f outside-ep.yaml 自定义 Endpoint 通常可用于服务迁移。当集群内的应用迁移到外部时,在 EP 资源中修改地址后,SVC 提供的访问 IP 地址可以保持不变。
配置别名
除了手动配置 EP 外,还可以设置域名作为转发目标。只需要在 SVC 配置文件中设置类型为 ExternalName 即可:
[root@server4-master ~]$ vi ext-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: exten
spec:
type: ExternalName
externalName: someapi.somecompany.com
ports:
- port: 80
targetPort: 6379
[root@server4-master ~]$ kubectl create -f ext-svc.yaml
[root@server4-master ~]$ kubectl get svc exten
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
exten ExternalName <none> someapi.somecompany.com 80/TCP 29s之后,集群内的 pod 可以通过访问 exten 这个 SVC 就能连接到外部域名 someapi.somecompany.com。这样的好处是不需要关心外部域名的 IP 地址,即使 IP 有变动也不会影响 SVC 的运行。
无头服务
假如客户需要获取一组 pod IP,默认情况下查询服务会返回服务的集群 IP。通过把服务 IP 设为 None,客户端可以通过一个简单的 DNS A 记录查找获取到属于该服务的所有 pod IP。这种服务叫做无头服务。
创建服务
配置 YAML 并启动服务:
[root@server4-master ~]$ vi kubia-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia-headless
namespace: default
spec:
clusterIP: None
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
[root@server4-master ~]$ kubectl create -f kubia-headless.yaml
service/kubia-headless created
[root@server4-master ~]$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 130d
kubia ClusterIP 10.107.244.106 <none> 80/TCP 3h43m
kubia-headless ClusterIP None <none> 80/TCP 3s
kubia-nodeport NodePort 10.99.116.227 <none> 80:30123/TCP 148m创建完毕后,可以看到服务没有集群 IP。
通过 DNS 查找
拉取一个能够进行 DNS 查询的容器后,进入 pod 执行 DNS 查找:
[root@k8s-master ~]$ kubectl run dnsutils --image=tutum/dnsutils --command -- sleep infinity
pod/dnsutils created
[root@k8s-master ~]$ kubectl exec dnsutils nslookup kubia-headless
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: kubia-headless.default.svc.cluster.local
Address: 10.244.1.38
Name: kubia-headless.default.svc.cluster.local
Address: 10.244.2.57
Name: kubia-headless.default.svc.cluster.local
Address: 10.244.2.58结果返回了 pod 的 IP,这与普通服务不同,比如 kubia 服务返回服务的集群 IP:
[root@k8s-master ~]$ kubectl exec dnsutils nslookup kubia
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: kubia.default.svc.cluster.local
Address: 10.102.7.149
[root@k8s-master ~]$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 24h
kubia ClusterIP 10.102.7.149 <none> 80/TCP 64s无头服务使用上与普通服务一样,客户也可以通过连接服务的 DNS 名称来连接到 pod 上,不过客户端直连到 pod 上,而不是通过服务代理。
无头服务仍然提供跨 pod 的负载平衡,通过 DNS 轮询机制实现。
发现所有 Pod
如果希望 pod 没有准备就绪也能被发现,可以在服务配置中添加注解:
metadata:
name: kubia-headless
namespace: default
annotations:
service.alpha.kubernetes.io/tolerate-unready-endpoints: "true"